 Кроме установки плагинов, настройка сайта предусматривает создание и правильное заполнение robots.txt. Это обычный текстовый файл, в котором содержатся специальные инструкции (директивы) для поисковых роботов. Настройка robots.txt для wordpress имеет свои особенности, о которых я расскажу в этой статье.
Кроме установки плагинов, настройка сайта предусматривает создание и правильное заполнение robots.txt. Это обычный текстовый файл, в котором содержатся специальные инструкции (директивы) для поисковых роботов. Настройка robots.txt для wordpress имеет свои особенности, о которых я расскажу в этой статье.
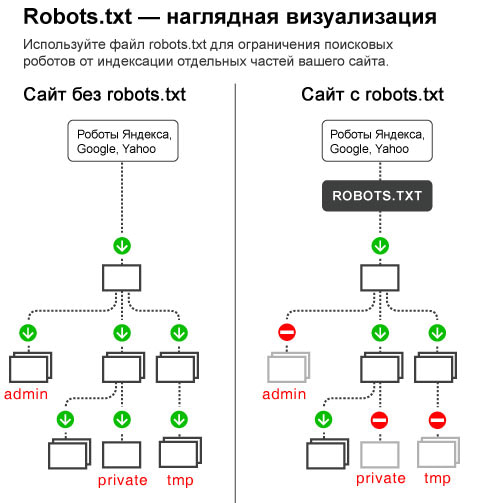
Зачем нужен robots.txt
Посредством данного файла можно:
- · запретить к индексации страницы и разделы вашего сайта, которые вы хотите скрыть от поисковиков (например, для того, чтобы в индекс не попала рабочая информация или страницы с дублирующимся контентом);
- · прописать правильное «зеркалирование» доменного имени;
- · указать ссылку на карту сайта;
- · задать определенный интервал между скачиваниями с сервера документов.
Значение основных директив
«User-agent:» – метка, к какому именно поисковому роботу относится информация, записанная после этой сроки. Например, «User-agent: Yandex» показывает, что дальше следуют директивы для поискового паука Яндекса, «User-agent: *» – инструкции касаются всех поисковиков.
«Disallow:» – запрет к индексации. Например:
- · Disallow: /wp-admin – запрет на индексацию папки «wp-admin»;
- · Disallow: /wp-login.php – запрет на индексацию страницы /wp-login.php;
- · Disallow: /*.pdf – запрет на индексацию всех имеющихся на сайте файлов в формате .pdf;
- · Disallow: /blog$ – запрет на индексацию страниц, находящихся в папке blog, за исключением вложений.
«Allow:» – разрешение на индексацию определенных страниц. Например, «Allow: /site/*.html» говорит поисковикам о том, что в папке site можно индексировать только страницы в формате .html.
«Crawl-delay:» – указание временного интервала (в секундах, может быть в диапазоне 1-10), с которым поисковики должны запрашивать файлы (страницы) с сервера. Используется для снижения нагрузки на сервер. Например, «Crawl-delay: 2» означает, что такой интервал должен составлять 2 секунды. Данную информацию в robots.txt для wordpress указывать необязательно.
Как правильно составить robots.txt для wordpress
1. В текстовом редакторе создаем файл robots с расширением txt, открываем его.
2. Задаем нужные директивы:
User-agent: * //указываем, к какому поисковику обращаемся. В данном случае инструкция касается всех поисковиков.
Disallow: /cgi-bin //закрываем от индексации папку cgi-bin.
Disallow: /wp-admin //закрываем от индексации папку wp-admin/
И так далее для каждой папки, которую мы хотим скрыть от поисковиков. Обычно для сайтов на вордпресс, кроме вышеуказанных папок, желательно закрыть от роботов wp-comments, wp-feed, wp-trackback, wp-content/themes, wp-content/plugins, wp-content/cache, wp-includes, */comments, */feed, */trackback.
3. Указываем основной хост:
Host: nash-sait.ru.
4. Указываем путь к карте сайта:
http:// nash-sait.ru/sitemap.xml.
5. Сохраняем созданный нами robots.txt для wordpress, копируем его в корень сайта.
Важно:
- · Редактировать и проверять правильность роботса можно с вебмастерских панелей поисковых систем. Для Гугла (google.com/webmasters) это будет пункт «Доступ для сканера» раздела «Конфигурация сайта», для Яндекса – «Анализ Robots.txt» раздела «Настройки индексирования» панели webmaster.yandex.ru.
- · Помните, что инструкции robots.txt безоговорочно принимаются к выполнению только пауками Яндекса. Гугл воспринимает их в качестве рекомендаций. Поэтому в его индексе могут появиться страницы, запрещенные вами к индексации посредством роботса.
- · Данный файл доступен для прочтения всеми пользователями. Не указывайте в нем пути к панелям управления или к админке. Тем более, что поисковики все равно не индексируют те страницы, для входа на которые необходимо указать логин/пароль.
Для тех, кому лениво разбираться 🙂 — готовый robots.txt здесь. Просто замените sales-text.ru на имя своего домена и положите файл в корневую папку сайта.
Привет ! Спасибо, за правильный robots.txt ! очень кстати…